
gRPC is a framework which is being used to build scalable and fast APIs. The framework from which it derives most of its positives is from the protocol it uses - HTTP/2. Apart from HTTP/2, it uses protocol buffer (protobuf) for the communication.
gRPC can be useful in circumstances like -
- large-scale microservices connections
- real-time communication
- Low power & low bandwidth systems
- Multi-language environments
Why Should We Care? Let’s talk Benefits
- The use of HTTP/2 over the TLS end-to-end encryption connection in gRPC ensures API security.
- gRPC provides built-in support for commodity features, such as metadata exchange, encryption, authentication, deadline/timeouts and cancellations, interceptors, load balancing, service discovery, and so much more.
- The prime feature of gRPC methodology is the native code generation for client/server applications.
- gRPC tools and libraries are designed to work with multiple platforms and programming languages, including Java, JavaScript, Ruby, Python, Go, Dart, Objective-C, C#, and more.
- Parsing with Protobuf requires fewer CPU resources since data is converted into a binary format, and encoded messages are lighter in size. So, messages are exchanged faster, even in machines with a slower CPU, such as mobile devices.
- Request and Response Multiplexing - Multiple requests/response in one single connection.
Underlying Concepts
Protocol Buffers
aka protobuf . It’s Google’s serialization/deserialization protocol that enables easy definition of services and auto-generation of client libraries. It is an IDL (Interface Definition Language).
Protobuf also has its own mechanisms, in contrast to a typical REST API, which only sends over JSON strings as bytes. These mechanisms enable faster performance and much smaller payloads.
Protobuf’s encoding process is quite intricate. Check out this extensive documentation if you want to learn more about how it functions.
Protocol buffers provide a language-neutral, platform-neutral, extensible mechanism for serializing structured data in a forward-compatible and backward-compatible way. It’s like JSON, except it’s smaller and faster, and it generates native language bindings.
Source: https://developers.google.com/protocol-buffers/docs/overview
The Protobuf compiler - protoc, generates client and server code that loads the .proto file into the memory at runtime and uses the in-memory schema to serialize/deserialize the binary message. After code generation, each message is exchanged between the client and remote service.
The first step when working with protocol buffers is to define the structure for the data you want to serialize in a .proto file. Protocol buffer data is structured as messages, where each message is a small logical record of information containing a series of name-value pairs called fields.
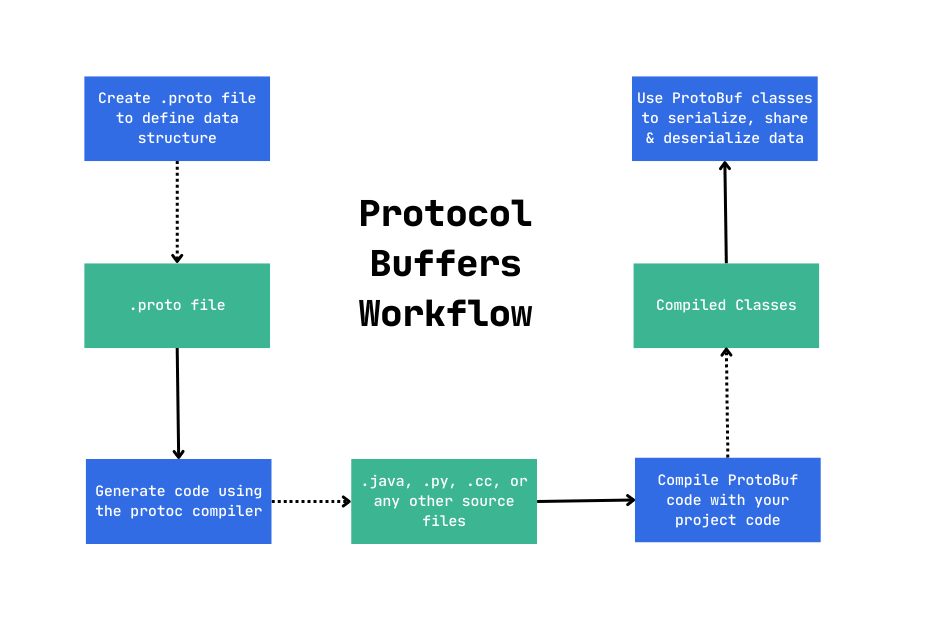 Source -
https://developers.google.com/protocol-buffers/docs/overview
Source -
https://developers.google.com/protocol-buffers/docs/overview
HTTP/2
It provides numerous advanced capabilities -
- Binary Framing Layer - HTTP/2 requests and responses are divided into small messages and framed in binary format for efficient message transmission. (Request/response multiplexing is possible without blocking network resources.)
- Streaming - Full duplex bidirectional streaming
- Flow Control - Extensive control over memory that is used to buffer in-flight messages.
- Header Compression - In HTTP/2, everything, including headers, is encoded before sending, which improves performance. HTTP/2 uses the HPACK compression method to share values that differ from previous HTTP header packets. Both on the client and server sides of HTTP/2, the header is mapped. Because of this, HTTP/2 can determine whether the header contains the same value as the previous header and will only send the header value in that case.
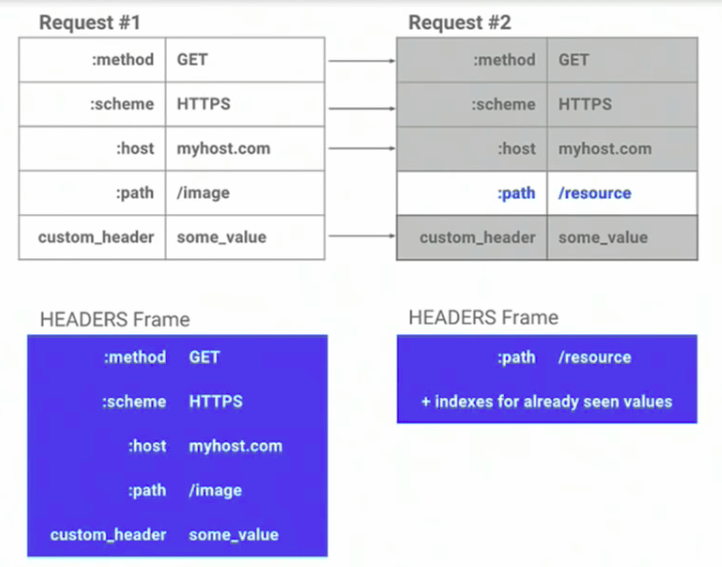 Source -
https://www.freecodecamp.org/news/what-is-grpc-protocol-buffers-stream-architecture/
Source -
https://www.freecodecamp.org/news/what-is-grpc-protocol-buffers-stream-architecture/
- Processing - Synchronous and asynchronous processing.
Streaming
It means that many processes can take place in a single connection, which allows sending/receiving multiple requests/response together over one single TCP connection using HTTP/2 protocol. There are three types of Streaming that can take place -
- Server Streaming RPCs - The server returns stream of data in an organized sequences until all the messages are over, in response to client request.
- Client Streaming RPCs - The client sends stream of data to the server instead of just one single message which is being processed and returned as a single response to the client.
- Bi-directional Streaming RPC - Both client and server sends sequential data in form of messages to each other which happens as independent operations.
Channels
They are the core concepts in gRPC. It extends the functionality by making, multiple streams of data over multiple concurrent connections, possible.
Architecture
Starting from a service definition in a .proto file, gRPC provides protocol buffer compiler plugins that generate client- and server-side code. gRPC users typically call these APIs on the client side (client stub) and implement the corresponding API on the server side (server stub).
Stub - Local object that implements the methods mentioned in the proto file into services.
- gRPC makes local procedure calls to the client stub with parameters to be sent to the server.
- Client stub serializes the parameters with marshalling process using Protobuf sends it through the local client library to the local machine. Then OS send the serialized data to the remote machine through HTTP/2.
- On the server side, OS receives packets and operating system calls the server stub procedure invocation using Protobuf, then do the processing and send back.
- Server stub send the encoded response to the client transport later and client gets back the result message.
If you all haven’t realized it yet, the RPC in gRPC stands for Remote Procedure Call. And yes, gRPC does replicate this architectural style of client server communication, via function calls.
References & Last Bytes
Next Steps -
- Learning to code using gRPC.
- Hacking gRPC
Below are some references, which help me understand the concepts -
- https://www.freecodecamp.org/news/what-is-grpc-protocol-buffers-stream-architecture/
- https://grpc.io/docs/what-is-grpc/core-concepts/
- https://developers.google.com/protocol-buffers/docs/overview
- https://www.wallarm.com/what/what-is-json-rpc
See you folks! Until next time ✌️