
In this blog post, we are going to talk about different components used in Kubernetes and what purpose each component serve. We will be talking about the following -
- Pods
- Service
- Ingress
- ConfigMap
- Secret
- Deployment
- StatefulSet
- ReplicaSet
- DaemonSet
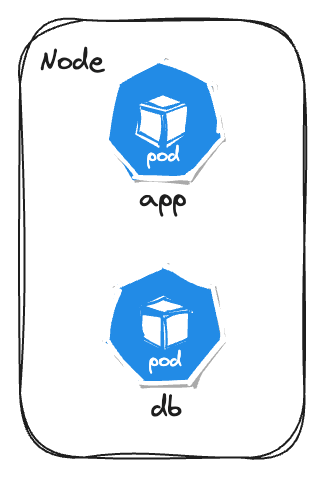
Use-case that will be used througout the blog will be hosting a web application with application code and database in different pods.
Before starting this blog, if you want to learn about the underlying concepts - Read “Kubernetes Concept”
Node and Pod
Node
Node is just like a virtual machine or a server where all the computations happen. There are generally two types of nodes -
- Master Node - Takes care of all the important tasks (master processes) like API Server, Controller Manager, Scheduler, etcd, etc.
- Worker Node - Higher workload which contains your deployments.
Pod
- Smallest unit in the kubernetes
- Abstraction over containers - It abstracts the container runtime (for example, Docker), so that we don’t need to directly interact with any container runtime and that can be easily replaceable.
- You can run multiple container per pod, but generally the setup is “1 container per pod”. You can run sidecars or helper containers along with the main pod.
Now, for each pod to communicate with each other Kubernetes provide a virtual network, which mean each pod (not the container) get a private IP address. These IP addresses can be used by pods to communicate with each other.
One of the important concepts in Kubernetes is that pods are ephemeral. This means that they can die very easily (application crashed, out of resources, etc.), and a new pod is spun up to replace that which has a new IP address than the previous pod.
Problem: Every time a container crashes the connection between the containers also break because of a new IP address configured to work with the containers 😰
Solution: Service & Ingress
Service and Ingress
Service
- Attached to each pod.
- Provides a permanent IP address and a DNS Hostname.
- Also acts as a load balancer (We will see about this later in this post)
- Lifecycle of the service is not connected to that of a pod.
- There are two types of services -
- Internal Service (Default) - To use for internal communication.
- External Service - To expose to the world.
- One can use the IP addresses (assocaited with the node) for external service to access the pods.
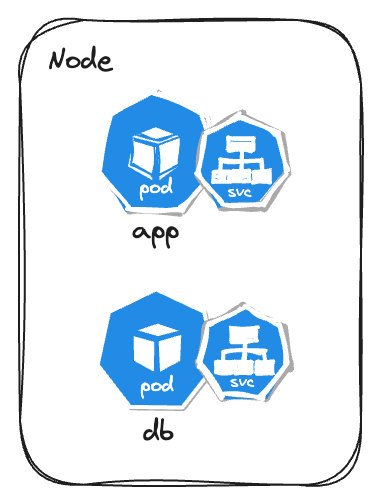
To access an external service the IP address will look something like - http://node-ip:port-number
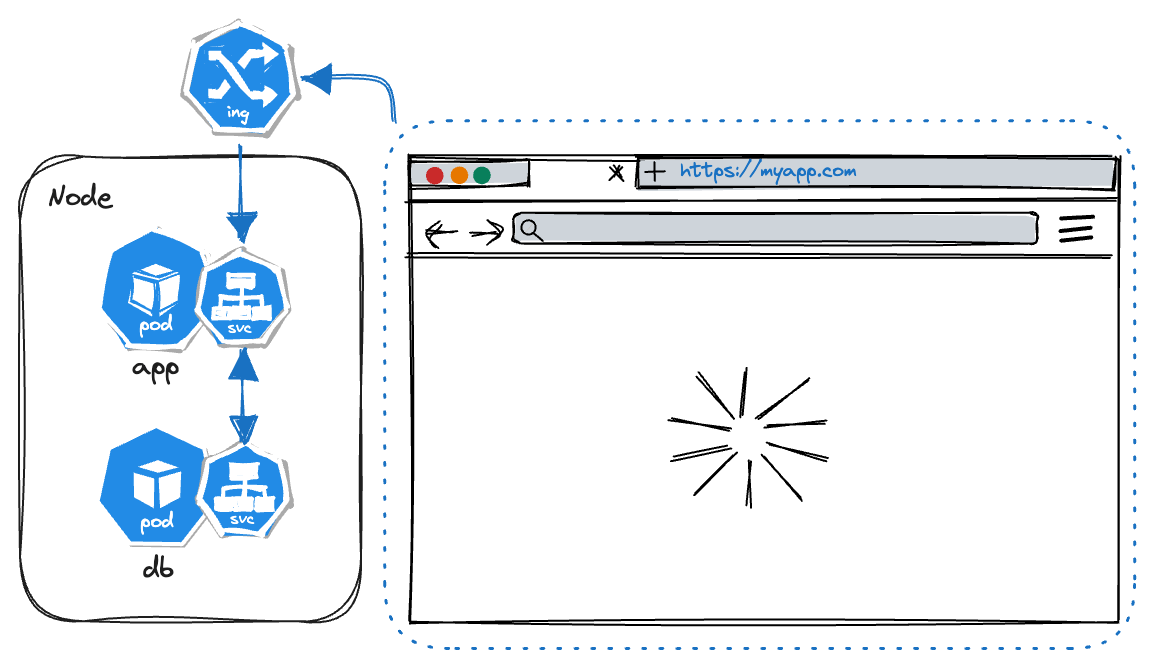
But the IP address are not very intuitive…to solve this problem kubernetes supports ingress.
Ingress
To user a SSL and a domain name that points to the service and gives a more intuitive way to connect for the users, ingress is being used.
Now, to connect and communicate to other pods, the connection strings (database URLs, names, credentials, etc.) need to be configured in the pods. Let’s say if an application wants to connect to the database, the application needs to be configured with the connection strings. One way is to build the application image with these data (Not a secure way to do this 😵) but for every change you will need to make modification, re-build the images and publish it and then use it. Too much hassle. To solve this problem, kuberenetes has ConfigMaps & Secrets.
ConfigMaps and Secrets
ConfigMaps
- External configuration to your application
- Used to store non-sensitive data
- Connects directly to the pod to provide the configuration it needs (like database name or URL)
Now to modify the connection string, we just need to update the ConfigMap and it’s done and updated for the application.
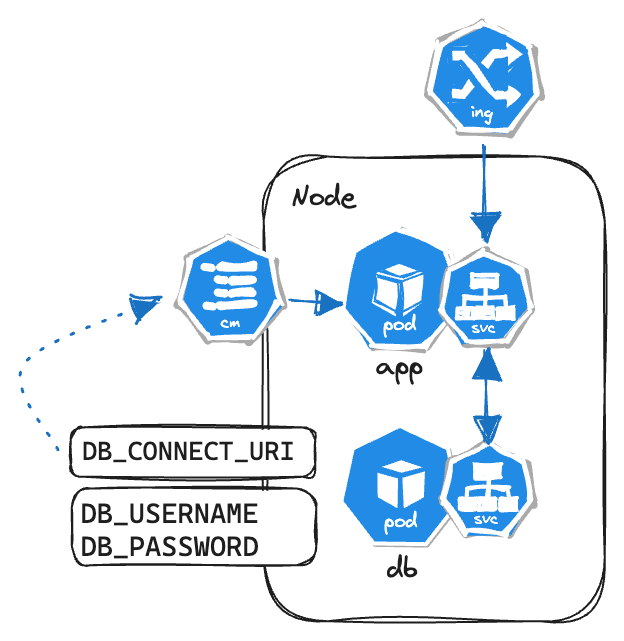
But the connection information also contains things like username and password, it’s not the best idea to store these in plain text in ConfigMaps.
To store sensitive data, Kubernetes secrets can be used.
Secrets
- Used to store data in base64 encoding
- Stored in etcd
- Must be paired with some third-party tool for secret encryption before storing them in here.
- One good thing about the secret is, since it’s a seperate components, it’s easier to implement RBAC to restrict access to the secrets.
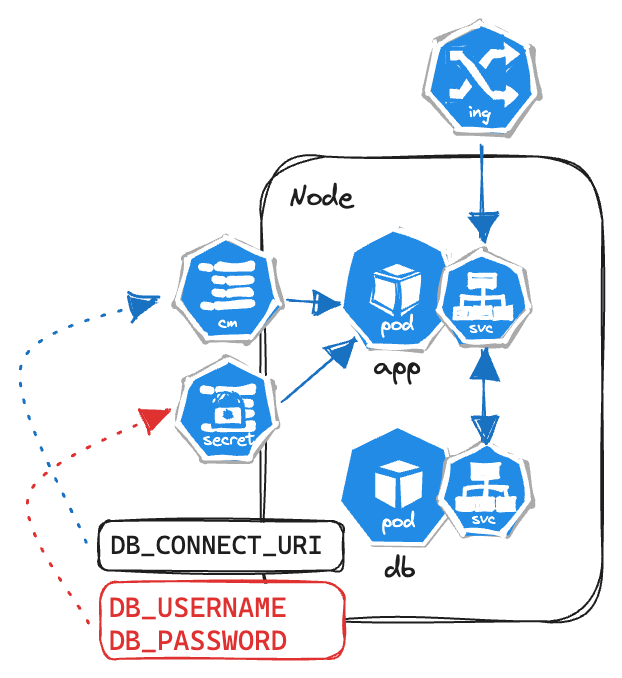
ConfigMaps or Secrets can be used inside the containers as a environment variable or in the properties file to be consumed by the application code.
Now, let’s talk some storage.
Volumes
- The database pod inside cluster stores some data in it, the problem arises when the pod restarts the data is gone (ephemeral). To solve that problem, another kubernetes component is being used called “Volumes”.
- Volume attaches a physical storage on a hard drive to the pod.
- This can be on your local machine (inside the cluster).
- External Storage (example, Cloud Storage)
- Kubernetes cluster does not manage any data persistance. So the administrator will have to take care of data backups, replications and management.
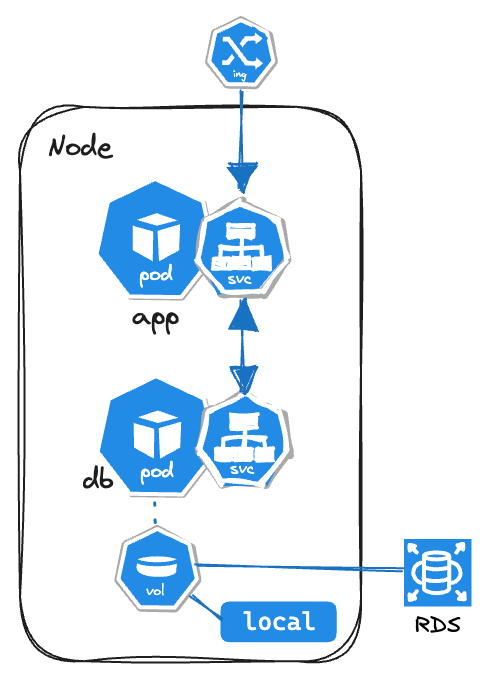
Deployment and StatefulSet
Deployment
In a single node setup, where there is only one pod running for serving the application. What happens if the pod restarts (crashes, image update, etc.)? There is a downtime in this setup.
The other questions, that we can ask if we want to upgrade the application version -
- Can we upgrade sequentially?
- Can we pause and resume the upgrade process?
- Can we rollback upgrade to previous stable release?
So, to tackle these problem, replicas needs to be created which share the same service.
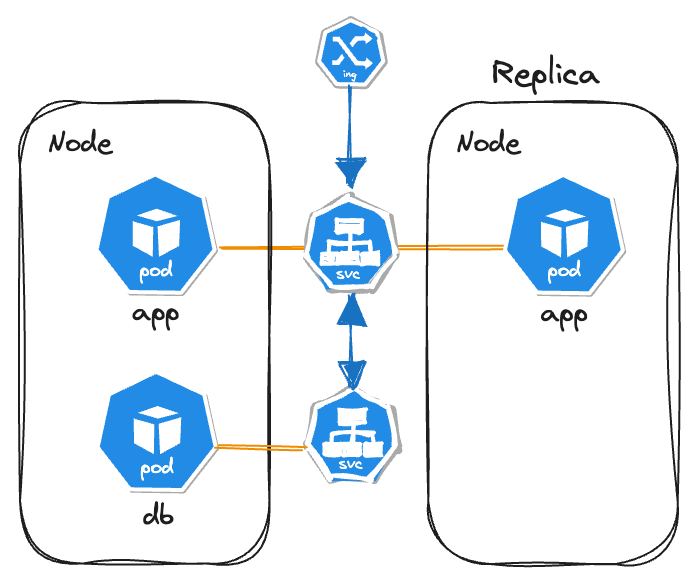
Now, to create this replicas we need not do it manually, we define a blueprint. This blueprint is called Deployments. So, if any pod dies service redirects the traffic to the another pod, and the application is accessible to the users.
As a administrator, you won’t be creating pods or ReplicaSet configs directly but deployments.
But in the above diagram, you can see in the replica only app pod is replicated. This is because Deployments are stateless.
If we create replica for the database, all the pods will share a data storage and there need to be a mechanism will take care of the actions like which pods are writing and reading to the storage, to avoid data inconsistencies.
This mechnism, in-addition to replication is offered by another Kubernetes Component - StatefulSet.
StatefulSet
- Any application that has a state should be created using
statefulsetas it helps in maintaining the state of the application or databases. - Takes care of replication and scaling the pods up or down.
- Make sure the database read and writes are synchronized, so no database inconsistencies are present.
Note: Creating and maintaining the statefulsets are more tedious task, so it’s a common practice to host the database outside the kubernetes cluster.
Now, let’s take a step back - deployments are used to scale up/down the pods by creating replicas for which it uses ReplicaSet. Let’s see what are the use-cases that cannot be satified by the use of ReplicaSet that are being solved using the DaemonSet.
ReplicaSet & DaemonSet
ReplicaSet
- Ensures that specific number of pod replicas are running at any point in time.
- In ReplicaSet we specify that at any point of time a node should have x number of pods. ReplicaSet tells that API Server that same information and scheduler takes care of the deployments.
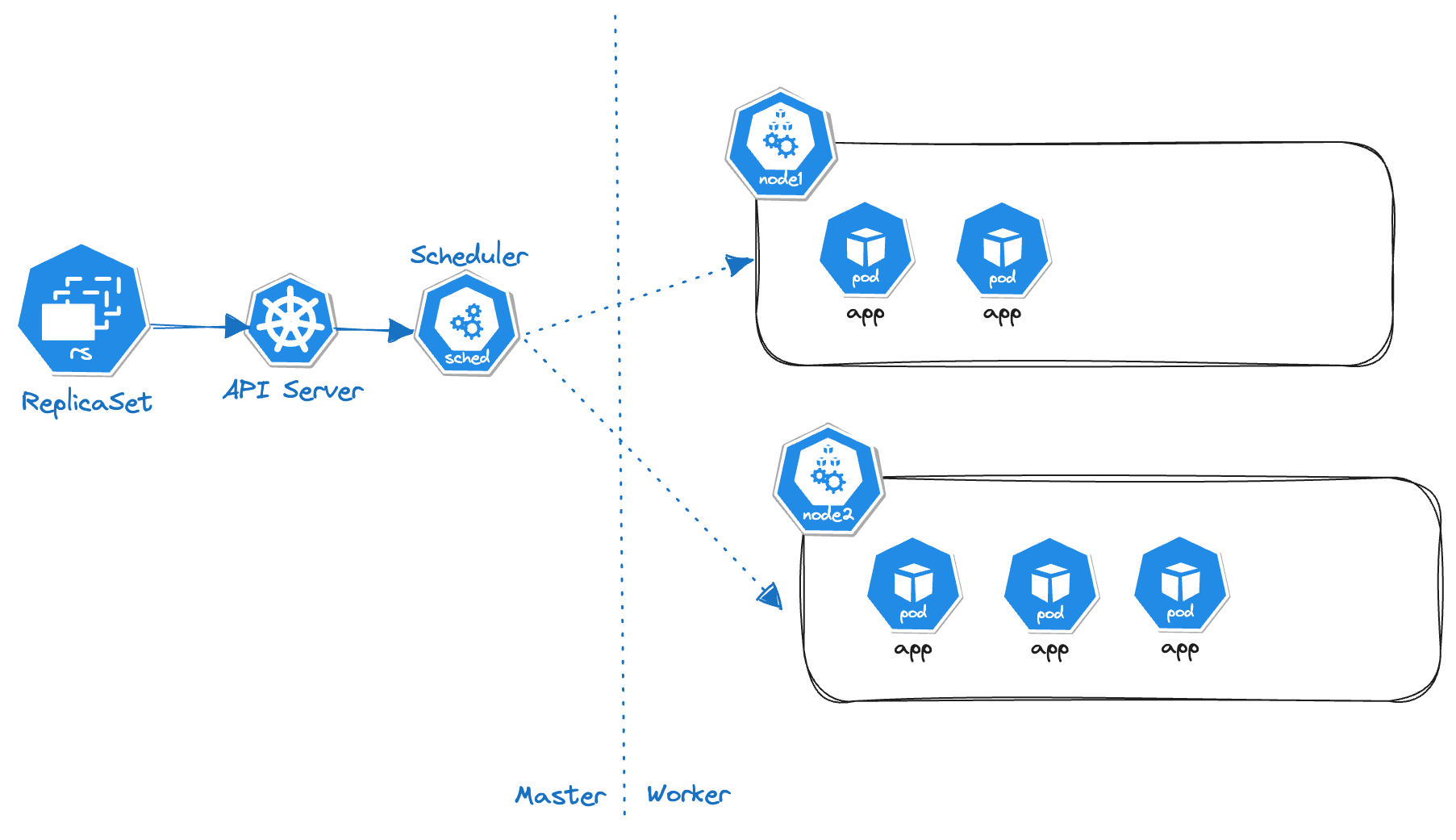
Now the problem arise, when we want to spin up a single instance of some service in each node. ReplicaSet won’t help us with that as it give scheduler the control on how to deploy pods by maintaining the defined state.
To solve this problem, there is a kubernetes component - DaemonSet.
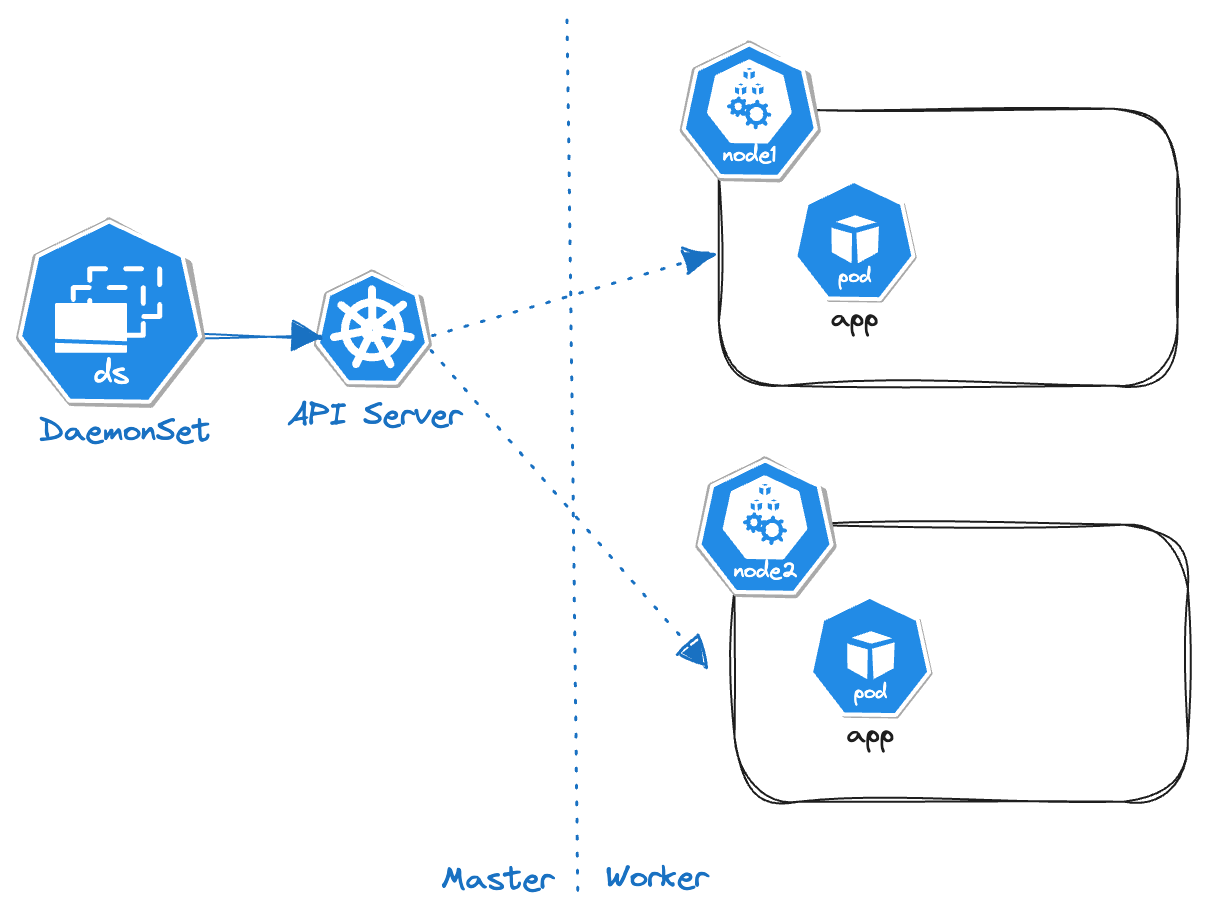
DaemonSet
- Example Use-case: If you want to install a monitoring agent or log collection agent on all the nodes, DaemonSet will help us in achieving this.
- DaemonSet can be used to deploy
- 1 pod per node
- 1 pod per subset of nodes (label the nodes and use them in DaemonSet Manifest to achieve this)
- If a node is newly added to the cluster, then the DaemonSet monitors this activity and adds the pod in this node as well.
Summary
- Pod - Abstraction over containers.
- Service - Communication
- Ingress - Route Traffic into the cluster
- ConfigMaps & Secrets - External Configurations
- Volume - Data persistence
- Deployments & StatefulSet - Pod blueprints and replication
- ReplicaSet & DaemonSet - Controlling pod deployment as per use-case.
And that’s a wrap for this blog! Keep learning and hit me up if you have any queries. Stay curious, stay awesome!